
考察:「今が大事なとき」
by ご近所のきよきよ
特異点解析が成ったかなと思って、ギザギザのある図形を用いてテストしたら、めちゃめちゃな結果が出ました。連続した線に成るはずが、所々に孤立点として認識しています。分岐点が連続してあったり、端点もそう。デバックしていったらどうも細線化のアルゴリズムがまずいらしい。また、特異点として認識するのに8近傍解析で行ったのですが、それだとタイトすぎて、曖昧性・・・ギザギザに対応できないようです。どうもプログラムを簡単に作りすぎたようです。曖昧性に本格的に挑むコードは相当複雑になりそうです。自然言語処理も図形処理もこの若葉の技術が基本となって来る予想ですので、ここは頑張らないといけないのです。
近傍解析を大領域で行うようにアルゴリズムを考えました。次の図のようなアイデアです。

赤枠の中は一つの分岐点として把握する。無論、これは大図形の場合で、細かな部分では近傍領域をもっと小さくしていく必要があります。また、連続していない線が結合しているように解釈すべきこともあります。誤差の問題・・・曖昧性の問題です。
つまり、問題を難しくしているのはこの曖昧性なのです。文脈処理を本格的に解決すべき時が来たようです。自然言語処理でも曖昧性を深く考えてきましたが、今回はもっと基本的なところで・・・知識ベースを基本にして大仕掛けで解決していこうと決心しました。連想によって、曖昧性を仮定値で置き換えるなど、試行錯誤アルゴリズムで実現していく・・・そんなこともやってみたくあります。
画像とか文字はイメージであり、自然言語をサポートするオントロジーの基盤です。これに対して自在の処理ができることはこれからの人工知能の発展に重要な意味をもつことになります。ここで、この段階で曖昧性問題をクリアしていくことは当を得たことだと思います。
曖昧性処理は次の3つの技術をベースとします。
(1)文脈処理
活性化している知識を管理し、重要事項とか意味の整合性とかを評価していく。そうして、現行の解釈を決定していきます。
(2)試行錯誤処理
文脈で不整合があればデータを改変して(仮定)、再解析して結果を評価していきます。
(3)永続化
膨大なデータを扱うため、基本的に永続化レベルのデータを扱います。
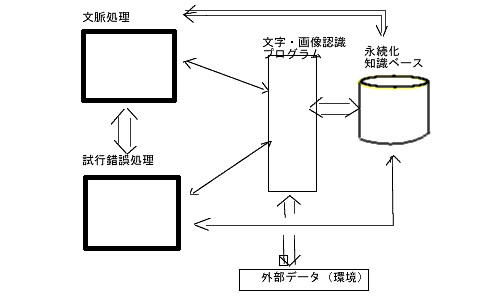
試行錯誤は元のデータを一部改変します。改変プロセスもリーズナブルでなくてはいけません。そんな連想関係も知識としてもちます。一つの試行錯誤プロセスは次の3つのデータを持った、オブジェクトということになります。
(1)元データと改変データのセット
(2)解析処理の名前
(3)解析処理のための制御データやローカルデータ
曖昧性を処理するには、文脈全体に渡る意味の整合性を評価していくことがポイントです。評価の前には無数の仮説が生成されるでしょう。全ての結果はリーズニングされていくでしょう。そうして刈り込まれていきます。評価の基本は、確固とした知識ベースがあるのです。脳の処理の基盤が脳地図でありますように、地図となる知識体系が文脈処理の基盤として存在しないといけないのです。
赤ん坊の誕生時には無数の神経細胞が生成されますが、正しい脳地図に結びつかなかった神経細胞は死滅します。曖昧性処理は無数の結果を生みます。しかし、確固とした知識ベースに照らしてリーズナブルなものだけが生き残り、未来をつくっていきます。そんなモデルを作るべきなのです。
おわり