考察:「モデル駆動型知識処理」
by ご近所のきよきよ
和葉をコーディングしていく前に、知識ベースの構造はどうあるべきかを考えておきたい。単語を学習すること、曖昧性を管理できること、文章の内容を理解していくこと、会話ができること。これらは全て知識ベースの構造に関わってくることです。シンプルだが強力な構造が必要です。人工知能としてどんな知識ベースを用意すべきか、ここで考えてみたいと思います。

単語も文章意味表現もモデルとして学習していき、利用されるようになっていきます。知識の単位は固まりなのです。
単語定義が固まりなのはよく分かることです。意味定義にはシーン、カットの記述が必要です。ステージは単語のくくりとして定義するのが自然です。単語がステージであれば、まとまりのあるコーパスの単位がステージですから、単語定義は自然に学習できていくもになります。なお、コーパスは何でもかでも蓄えるコーパスがあって、その内の、まとまりを感じる物がステージとして切り出されて単語コーパスになるのです。単語コーパスはモデルとなるものです。ステージもモデルです。そしてモデルは意味の纏まったコーパスなのです。コーパスは意味記号であり、イメージであり、論理化されたイメージでもあります。こうして考えていくと、若葉も和葉も青葉も瑞葉も統一的にモデル駆動型知識処理として構成できます。モデル駆動型知識処理は人工知能の基盤技術なのです。人工知能は知識の固まりであるモデルを単位として処理が成されていくべき物なのです。
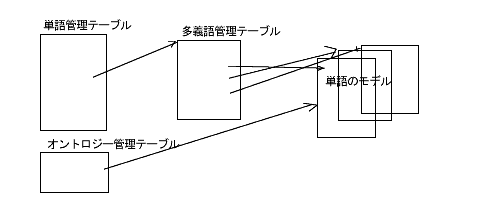
オブジェクトはモデルとして管理します。単語はオブジェクトを指します。だから単語はモデルとして管理されます。ただ、単語には多義語問題、曖昧性問題がありますから、モデルとして知識の固まりを管理するだけでなく、多義語管理テーブルも必要になります。多義語テーブルを単語の内部表記で名前つけして、多義語テーブルから曖昧性の無い、唯一のモデルを指していくようにするのです。そんな工夫が必要でしょう。
意味記号には意味記号に対応するプロセスを配して、学習によって、意味記号を柔軟に処理していくようになっていること。これで、モデル駆動型知識処理は人工知能の基盤技術となっていくでしょう。