
by ご近所のきよきよ
若葉で文字認識にトライし始めました。昔、雫プロジェクトで手がけていたものです。その拡張です。その完成形といってもよい。わくわくしますね。思い出してみれば、私の最初の特許は図形処理でした。つまり私の基本は図形処理でしたから、この図形認識で製品化を狙うことは、古巣に錦の御旗を立てるようなものです。気張ります。
基本の解析項目は次の図のようなものです。図は、線分と領域からなるものとします。
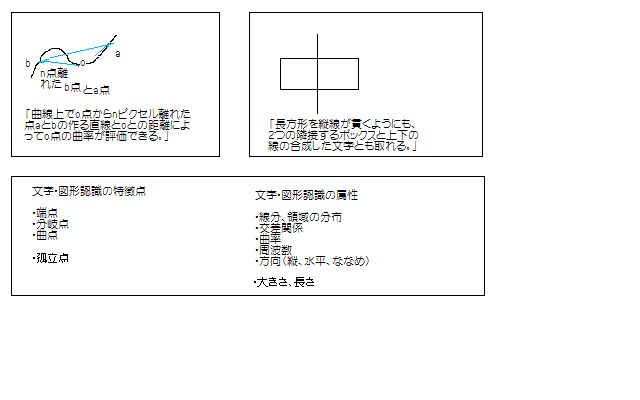
解析項目はすべて曖昧性のある量です。文脈を管理しながら文字、図形の意味を同定していくことになります。そしてそれは、知識ベースの下で処理していくことになります。意味記号群の作る、認識結果を基に文脈とて、誤差範囲を数値で決めて、それを文脈管理テーブルに持ち、試行錯誤の解析を繰り返していくことになります。候補を1つに絞るまで試行錯誤を続けます。試行錯誤は弛緩法として実現していきます。膨大なデータを創っていくことになりますので、解析結果は逐次永続化していきます。それが知識ベースの下で解析を行う理由です。
若葉は若き頃の仕事の集大成を行うものになりそうです。図形処理と文字書き、図形認識と文字認識・・・・・そんなものをライブラリにして開発者の勉を図るものにしていきたく思います。もちろん、大きい枠組みでの文字・図形認識システムとして簡便に使えることも目指します。若葉は私の仕事の原点に回帰していくものということで、なんか人生が収束していくのを感じますね。
おわり